Transactions and Locking¶
When you transfer money from your savings account to your checking account, you expect that both accounts will reflect the updates. If the bank loses connectivity to its database before your money is deposited into your checking account, you expect that no money will be debited from your savings account. A database that supports transactions is able to guarantee that either both of these steps succeed or both steps fail.
A transaction is a unit of work that either completes or fails as a whole. A transaction has the following pattern:
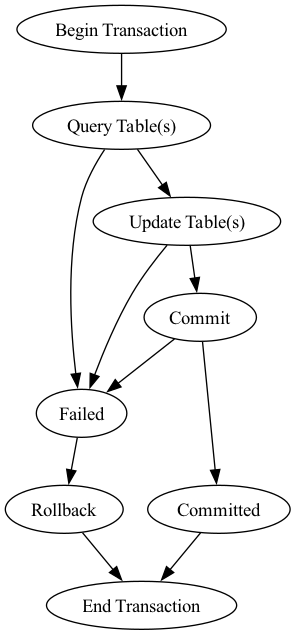
To be reliable, a transaction must have ACID properties.
Atomicity. A transaction must be an atomic unit of work. Either all the updates succeed or the database is left unchanged.
Consistency. When completed a transaction should leave the database in a consistent state. Internal data structures such as indexes must be correct at the end of the transaction.
Isolation. Modifications made by the current transaction must be isolated from modifications made by other concurrent transactions. Updates can be lost if one transaction is in the process of modifying data but has not yet completed, and then a second transaction reads and modifies the same data. Isolation is enforced through locking.
Durability. After a transaction has completed its effects are permanent. Once the user has been notified of a transaction’s success the transaction must not be lost. Many DBMS implement durability by recording transactions in a transaction log that can be reprocessed to recreate the system state right before any later failure.
Locking Overview¶
Transaction isolation is accomplished through the use of locking. Locking is a synchronization mechanism that guarantees exclusive access to an object. All databases that support multi-user access use some form of locking.
The example below shows a problem that arises when locking is not used. Two users simultaneously gain access to an account. The twenty dollar debit by the first user is overwritten when the second user stores their updated record.
Locking prevents the second user from accessing the account until the first user releases control, guaranteeing both updates are recorded.

Databases support a variety of locking mechanisms. Locks can be applied at the row, page, or table level. Using low-level locks, such as row locks, increases concurrency by decreasing the probability that two transactions will request locks on the same piece of data at the same time.
DataFlex Locking¶
DataFlex programs alter data in tables either by using data-dictionaries (DDOs), or procedurally through manual coding.
Using DDOs¶
DDOs use the REQUEST_SAVE or REQUEST_DELETE method to modify tables. Both methods automatically implement transactions, which fully support all of the ACID property requirements.
Procedurally¶
DataFlex also supplies the following commands to manually code procedures that perform database updates:
BEGIN_TRANSACTIONto define the beginning of a transaction
END_TRANSACTIONto commit a transaction
ABORT_TRANSACTIONto rollback a transaction
LOCKto lock the database
REREADto lock the database and refresh all active buffers
UNLOCKto unlock the database
SAVERECORDto update fields with new values
In either case, the native DataFlex database only supports table level locking. This means that a lock placed on a DataFlex table prevents anybody else from updating any rows in that table.
Native DataFlex allows other processes to have read access to data that has been locked by a process in a transaction/LOCK/REREAD scenario. SQL on the other hand, denies other processes access to rows locked inside a transaction block. Outside of a transaction block, SQL behaves like native DataFlex; locked rows can be read but not updated.
Locking with Mertech Drivers¶
Mertech drivers use row level locking. Since DataFlex locking is based on tables, this is an added benefit for using the client/server solution in medium to large multi-user environments. If a DataFlex program contains REREAD, the driver re-finds the record in the record buffer and locks the current record until the transaction is completed. Any record not explicitly locked can be updated by other users. This provides a great boost in concurrency over the native DataFlex database.
Dealing with Deadlocks¶
Deadlock occurs when one process holds a lock and then attempts to acquire a second lock. If the second lock is already held by another process, the first process is blocked. If the second process then attempts to acquire the lock held by the first process, the system has deadlocked.
The example below shows a deadlock that occurs when two processes attempt to transfer funds between the same two accounts.
Deadlocks are normally avoided by always locking in the same order. The above example violates this rule. The first process locks the checking account and then attempts to lock the savings account, while the second process locks the savings account and then attempts to lock the checking account.
Note
The entire table is locked in native DataFlex. Only an individual row needs to be locked when the Mertech drivers are used, lessening the chance for deadlock.
Deadlocks in the drivers are detected and passed back to DataFlex, which rollbacks the transaction and retries it. If the deadlock persists it is reported as an error back to the user.
Note
Different SQL databases have different options for dealing with deadlocks. If you encounter a deadlock, refer to the online documentation for the particular database. Trace files may be available to help identify which tables and queries were involved in the deadlock.
Some tips for avoiding deadlocks:
Set Smart_Filemode_State to true (default) for all DDOs in the Data Dictionary, so smart table locking is used.
If using
REREAD, explicitly list the tables you want to lock, otherwise all open tables are locked.Open tables that are not updated as read only.
Properly setup aliases, if an alias is set up incorrectly, the application can end up waiting for itself.
Always lock in the same order. If two applications access the same database, make sure the internal table numbers have the same relative order.
Use the Index Maintenance utility to verify that all indexes have been created. Missing indexes slow down finds and leads to longer held locks.
Familiarize yourself with Mertech’s macro commands, for example to use embedded SQL to move processing to the server side.