Database Design¶
Good database design is the key to obtaining accurate information and achieving optimum database performance. The design process includes the following steps.
Plan: Identify the purpose of the database. Is the database a simple order entry system or might it be used for sales forecasting in the future?
Organize the Information: Determine the types of information you want to store in the database, such as customer information, product information, and purchase orders. Organize this information into subjects. Each subject becomes a table.
Assign Data Elements to Each Table: Decide which items should be stored in each table. Each item becomes a column. For example the customer table might include the customer name and customer address.
Follow these rules when defining table columns:
Naming: Follow an agreed upon naming convention for table and column names to improve readability.
Do Not Duplicate Data: Duplicate or redundant information not only wastes space, but also increases the likelihood of errors and inconsistencies. Store the customer name in the customer table; do not duplicate the customer name in the purchase orders table.
Do Not Store Calculated Data: Do not store running totals (for example number of orders placed by a customer) in a table column. This requires that all add, modify, and delete code update this field each time a change occurs. The total can instead come from doing a count of the number of orders this customer has placed. Embedded SQL or even computed columns can also be used.
Store Information in its Smallest Logical Parts: Break information into logical parts so you can retrieve individual facts later. Create a separate field for first name and last name, instead of one name field.
Identify Primary Keys: Each table should include a column or set of columns that uniquely identifies each row stored in the table. Choose a primary key whose value will not change frequently. Often, a unique number (e.g., order number or customer ID) is used as the primary key. The primary key is normally the clustered index, and controls the physical layout of data in the table. Finding on a primary key is fast since it involves only one lookup. For other indexes the index data is first searched to find the location of the data row, followed by the actual data row lookup.
Determine Relationships: Relationships enable you to prevent redundant data. Look at each table and decide how the data in one table is related to the data in other tables. Add fields to tables or create new tables to clarify the relationships. Use foreign keys to identify relationships between tables. A foreign key is an index in one table that matches the primary key column in another table.
There are various types of relationships that can exist between two tables:
Type
Description
Symbol
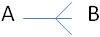
One to (zero or) one
A row in table A can have no more than one matching row in table B, and vice versa. This type of relationship is not common but might be used to e.g., hide private information in a separate table. Example: Each customer can have only one social security number and each social security number is assigned to only one customer.
One to (zero or) many
A row in table A can have many matching rows in table B, but a row in table B can have only one matching row in table A. This is the most common relationship. Example: a customer can have many orders, but each order is associated with only one customer.
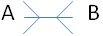
Many to Many
A row in table A can have many matching rows in table B, and vice versa. Example: A customer can have multiple addresses and an address can be shared between multiple customers.

Overlaps¶
The Unicde Edition of Flex2SQL no longer has support for overlaps as this practice is not compatible with Unicode character conventions. If you have overlaps within yoru existing database tables and wish to move to Flex2SQL Unicode Edition, you’ll first need to remove these from your codebase and database.
Relationships¶
The objective of a relationship is to isolate data so that changes made in one table are propagated through the rest of the database via the defined relationships. Above examples show the importance of relationships in good database design.
The Flex2SQL Classic Migration Utility provides a way to synchronize relationships between DataFlex tables and the SQL Server backend (Maintenance > Synchronize Relationship). Enforcing relationships on the SQL Server helps ensure data consistency.