Scenarios using the GUI Migration Utility¶
This section describes migration scenarios that can be used to consolidate data directories, maintain data segregation, perform load balancing and more.
A Basic Migration¶
The Mertech Migration Utility creates an SQL server database from a Btrieve/Pervasive.SQL transactional database to allow Pervasive developers to offer all the features available on SQL servers without changing source code or compromising on performance.
A sample Pervasive data directory is shown below.
C:\MyApp\DATA
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
The DDF files contain the database file names (FILE.DDF), field names including offsets and data types (FIELD.DDF) and indexes (INDEX.DDF). The following steps are taken to migrate a Btrieve/Pervasive.SQL transactional database to an SQL database.
The developer:
Launches the Migration Utility
Logs in by entering the target server name, user name and database name.
Selects the FILE.DFF containing the tables to be migrated to the target database.
The Migration Utility:
Reads the DDF files to determine the structure for the migrated tables.
Uses this information along with the login data to create the tables on the SQL server.
Copies the existing data to the new tables.
Stores the table structure in intermediate (INT) files.
The same data directory after migration:
C:\MyApp\DATA
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
MARKETING_MKD.INT
PURCHASING.MKD
PURCHASING_MKD.INT
SALESPEOPLE.MKD
SALESPEOPLE_MKD.INT
Tables created in the target SQL database:
MARKETING
PURCHASING
SALESPEOPLE
What happens during runtime?¶
When you launch the BTR2SQL Migration Utility, a Login dialog box prompts for a server name, user name and database name. These entries determine the target backend for the migrated files.
Similarly, when the operator runs the application, a Server Login dialog box displays to again obtain the target backend information. When the application issues a B_OPEN to open a file (for example MARKETING.MKD), the Mertech driver locates the associated INT file (MARKETING_MKD.INT) in the data directory and uses the login information along with the table structure stored in the INT file to connect to and open the converted SQL table.
Creating tables on the fly
In addition to using the INT file to connect to and open a converted table, the Mertech driver also uses the INT file to create tables at runtime.
When an application issues a B_CREATE, the driver looks to see if an INT file already exists for the file. If there is an existing INT file, the driver compares its contents with the index definitions in the new create structure. If they look like a match, the driver uses the definitions in the INT file to create the table on the server. This allows you to have pre-existing INT files (with full field definitions) for temp tables for instance.
There may be times when you do not want an existing INT file to be used, in that case you can set the keynum value for B_CREATE:
B_CM_OVERWRITE_IGNORE_INT_FILE = -6
Opposite this, perhaps you want the driver to always use the definition in the INT. Two more flags force this behavior and the FILESPEC in the dataBuffer is completely ignored:
B_CM_OVERWRITE_FORCE_INT_FILE = -99
B_CM_NOOVERWRITE_FORCE_INT_FILE = -100
To prevent an INT file from being deleted when a table is dropped, you can set the PERMANENT_INT token in the INT file to YES (the default setting is NO):
PERMANENT_INT YES
See also
Common folder layouts¶
It is common in the Pervasive environment to create files with the same name residing in different folders. For example the C:\MyApp\DATA directory might contain subdirectories for the central, east and south regions of a company. Each subdirectory might contain the marketing, purchasing and sales person information for that region.
C:\MyApp\DATA
CENTRAL\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
EAST\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
SOUTH\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
The problem when migrating these files to the SQL side is that different tables with the same names will collide if stored in the same database. Mertech provides several ways to resolve this problem. You can:
Migrate each folder to a different database on the same server (refer to Distributing Tables to a Different Database or Schema).
serv.db1.dbo.purchasingserv.db2.dbo.purchasingMigrate each folder to a different schema name, or user on Oracle (refer to Distributing Tables to a Different Database or Schema).
serv.db1.user1.purchasingserv.db1.user2.purchasingMigrate all folders to the same database and schema but attach a custom prefix to the table names (refer to Using a Custom Prefix or Postfix to Distinguish Tables).
serv.db1.dbo.cust1_purchasingserv.db1.dbo.cust2_purchasing
Distributing Tables to a Different Database or Schema¶
The Mertech drivers work seamlessly in a distributed environment. Consider the following scenarios:
You choose to leave some files in Pervasive, while migrating others to an SQL backend. This could be an interim step during the migration process to test the migration.
You might distribute tables across different databases to balance the load or to separate data by region or business unit.
Security settings may dictate your choice of where tables are stored.
The Mertech drivers support all of these scenarios.
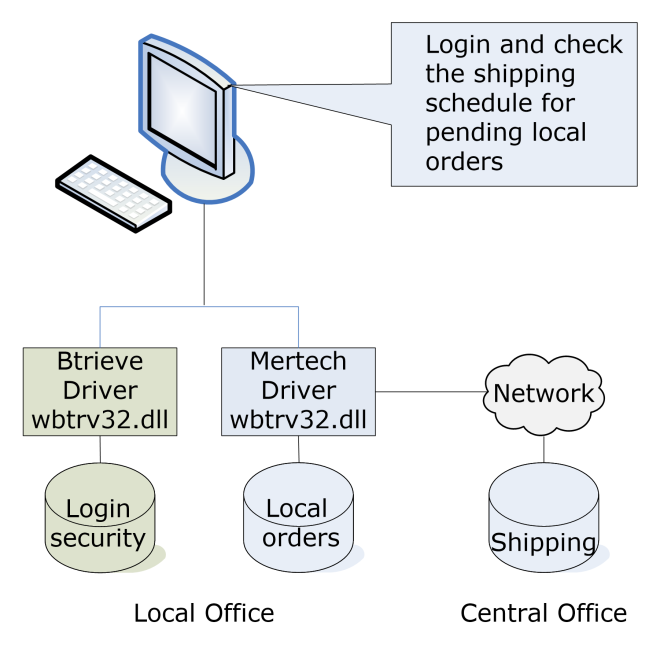
Figure 23 Distributed Environment
Start the Migration Utility and login.
Select the required File.DDF.
Select the individual files for this target database.
<Right-click> and choose Convert to Database.
Uncheck the Get Server Name from Login, Get Schema from Login and Get Database Name from Login check boxes so this information is stored in the INT files.
Click OK.
To migrate additional files to a different database:
Choose File | Select Database and pick a different database from the Select Database dialog box.
If required, choose a new FILE.DDF.
Select the individual files for the new database.
<Right-click> and choose Convert to Database.
Uncheck the Get Server Name from Login, Get Schema from Login and Get Database Name from Login check boxes so this information is stored in the INT files.
Click OK.
To migrate files to a different schema:
Choose File | Login and provide different credentials.
Note
The selected user must have object creation rights.
If required, choose a new FILE.DDF.
Select the individual files for the new schema.
<Right-click> and choose Convert to Database.
Uncheck the Get Server Name from Login, Get Schema from Login and Get Database Name from Login check boxes so this information is stored in the INT files.
Click OK.
Other options¶
The BTR2SQL Migration Utility allows you an easy way to distribute an MS SQL database by selecting separate Filegroups for tables, indexes, and text storage (Convert File dialog box | MSSQL tab). Choosing separate Filegroups can streamline administration and increase data access speed.
The BTR2SQL Migration Utility also allows Oracle users to choose different tablespaces for index and data tables (Convert File dialog box | Indexes tab).
You can also choose to migrate some tables to one tablespace and other tables to another tablespace using the scripting option:
Use the BTR2SQL Table | Generate | SQL Script for Creating Tables option.
Modify the generated script as needed.
Run the modified script to create the tables.
Use BTR2SQL Table | Copy Data option to copy the data.
Using a Custom Prefix or Postfix to Distinguish Tables¶
Instead of using a different database or schema as in the previous scenario, you might want to create separate tables for each region. To avoid the conflict in names, you can include either a prefix such as SOUTH_ or a suffix like _EAST. During the migration, the tables are created with this addition so SALESPEOPLE becomes SOUTH_SALESPEOPLE or SALESPEOPLE_SOUTH.
You specify the prefix or suffix in the data directory configuration file, mds.ini. The mds.ini file contains a number of settings to help automate and consolidate information needed by the BTR2SQL driver at runtime. Mds.ini is placed in the folder where the application’s data files are usually stored and works in conjunction with the INT files that have replaced the original Btrieve data files.
The Table-Prefix and Table-Postfix settings in the mds.ini file can be used to create unique table names.
The example Pervasive directory before migration:
C:\MyApp\DATA
CENTRAL\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
EAST\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
SOUTH\
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
PURCHASING.MKD
SALESPEOPLE.MKD
Place a copy of the mds.ini file in each data directory.
Note
A sample mds.ini file can be found in the installation folder (
<Program Files>\Mertech Data Systems\DB Drivers\Btrieve\sdk\samples).Edit the mds.ini file to add the required prefix or suffix for the data directory. For example, edit the mds.ini file in the CENTRAL data directory to add the table prefix
CENTRAL_.[SQL_BTR] Table-Prefix=CENTRAL_
Migrate the files in each data directory to your SQL Server.
Open the Migration Utility, login and select the associated FILE.DDF.
Select the Pervasive files to be migrated.
<Right-click> and choose Convert to Database
Click OK.
This 1) creates the SQL tables with the entered prefix 2) copies the existing data into the SQL tables, and 3) generates the intermediate files (.INT).
The same data directories after migration:
C:\MyApp\DATA
CENTRAL\
mds.ini
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
MARKETING_MKD.INT
PURCHASING.MKD
PURCHASING_MKD.INT
SALESPEOPLE.MKD
SALESPEOPLE_MKD.INT
EAST\
mds.ini
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
MARKETING_MKD.INT
PURCHASING.MKD
PURCHASING_MKD.INT
SALESPEOPLE.MKD
SALESPEOPLE_MKD.INT
SOUTH\
mds.ini
FIELD.DDF
FILE.DDF
INDEX.DDF
MARKETING.MKD
MARKETING_MKD.INT
PURCHASING.MKD
PURCHASING_MKD.INT
SALESPEOPLE.MKD
SALESPEOPLE_MKD.INT
Tables created in the target SQL database:
CENTRAL_MARKETING
CENTRAL_PURCHASING
CENTRAL_SALESPEOPLE
EAST_MARKETING
EAST_PURCHASING
EAST_SALESPEOPLE
SOUTH_MARKETING
SOUTH_PURCHASING
SOUTH_SALESPEOPLE
Specifying the path to the INT files¶
In the scenario mentioned above, where a similar set of data files is duplicated to multiple subfolders, the INT files in each folder would be the same. While this is not a problem, it can be desirable to consolidate the files for easier maintenance.
When you migrate to SQL, you would deploy this structure (plus your application and Mertech driver):
C:\MyApp\DATA
CENTRAL\
mds.ini
MARKETING_MKD.INT
PURCHASING_MKD.INT
SALESPEOPLE_MKD.INT
EAST\
mds.ini
MARKETING_MKD.INT
PURCHASING_MKD.INT
SALESPEOPLE_MKD.INT
SOUTH\
mds.ini
MARKETING_MKD.INT
PURCHASING_MKD.INT
SALESPEOPLE_MKD.INT
Or, you can add an INT-Folder entry to the mds.ini file to tell the driver where to find the common set of INT files, and instead deploy something like this:
C:\MyApp\DATA
INTFILES\
MARKETING_MKD.INT
PURCHASING_MKD.INT
SALESPEOPLE_MKD.INT
CENTRAL\
mds.ini
EAST\
mds.ini
SOUTH\
mds.ini
What this has done is eliminate the duplicated INT files. You now only have one folder to maintain for the INT files. You still need each data folder as you would in Btrieve, but you just need the mds.ini file in it with the appropriate INT-Folder and Table-Prefix entries.
[SQL_BTR]
INT-Folder=..\INTFILES
Table-Prefix=CENTRAL_
Note
Instead of creating CENTRAL, EAST and SOUTH directories for the mds.ini files, you can use the MdsSetSetting API to create virtual mds.ini files in memory for each folder. For example:
MdsSetSetting("C:\MyApp\DATA\CENTRAL","INT_Folder","..\INTFILES")
MdsSetSetting("C:\MyApp\DATA\CENTRAL","Table-Prefix","CENTRAL_")
What happens at runtime?¶
When an application issues the B_OPEN API to open a file (for example MARKETING.MKD), the Mertech driver opens the mds.ini file in the data folder and uses the path defined by the INT-Folder entry to locate the associated INT file (..\INTFILES\MARKETING_MKD.INT). The driver reads the INT file and uses the information to connect to and open the converted SQL table.
A Real-life Example¶
A Btrieve application maintains a master catalog of office supplies and creates customer-specific catalogs on the fly at runtime. The application was migrated to MS SQL Server and the deployed data directory and database look like this.
Data directory:
C:\MyApp\DATA
INTFILES\
MASTER_DAT.INT
The MS SQL database:
MASTER
The MASTER_DAT.INT file has the read-only attribute checked and the PERMANENT_INT token set to YES.
Customer “A” requests a supply list specific to his business. The application creates a new folder, CustomerA:
C:\MyApp\DATA
INTFILES\
MASTER_DAT.INT
CUSTOMERA\
The application also creates an mds.ini file in that folder:
C:\MyApp\DATA
INTFILES\
MASTER_DAT.INT
CUSTOMERA\
mds.ini
The mds.ini file contains the INT-Folder entry to show where the INT file is that contains the catalog structure. The mds.ini file must also provide credentials for accessing the server and some way to distinguish this catalog from other catalogs.
Note
The mds.ini file should be the only file in the CUSTOMERA folder. If the INT file is placed in the CUSTOMERA folder, the mds.ini INT-FOLDER entry is ignored.
This example mds.ini file uses Table-Prefix to distinguish this table from others. A different schema or user could also be used.
[SQL_BTR]
INT-Folder=..\INTFILES
Server=testserver
Database=testdb
Schema=dbo
Table-Prefix=CustA_
Note
Instead of creating the CUSTOMERA directory containing an mds.ini file, you can use the MdsSetSetting API to create a virtual mds.ini file in memory for CUSTOMERA. For example:
MdsSetSetting("C:\MyApp\DATA\CUSTOMERA","INT_Folder","..\INTFILES")
MdsSetSetting("C:\MyApp\DATA\CUSTOMERA","Table-Prefix","CustA_")
When the application issues a B_OPEN (C:\MyApp\DATA\CUSTOMERA\MASTER.DAT):
The driver opens the mds.ini file in the CUSTOMERA subdirectory and is redirected by the INT-Folder entry to the MASTER_DAT.INT file in the
..\INTFILESsubdirectory.The driver reads the MASTER_DAT.INT file and tries to open testserver/testdb.CustA_MASTER
The table does not exist so BTRIEVE Status 12 (File does not exist) is returned.
The application executes a B_CREATE:
The driver repeats the same logic to locate the INT file (actually, the mds.ini and INT file are obtained from memory cache).
The driver creates the CUSTA_MASTER table based on the definitions in the MASTER_DAT.INT file.
Data directory:
C:\MyApp\DATA
INTFILES\
MASTER_DAT.INT
CUSTOMERA\
mds.ini
The SQL database:
MASTER
CUSTA_MASTER
Note
If you want to use a unique schema/user or database instead of a table prefix for each catalog, you need to execute the SQL commands to do this before accessing tables from the new data folder. BTR2SQL includes an embedded SQL API.
See also
Pros and Cons of each Migration Option¶
Below is a comparison of the three main approaches for resolving table name collisions when migrating multiple data folders.
Migrate each folder to a different database¶
PROs
An easy way to perform load balancing by distributing data across different databases or hard disks.
You can assign different user credentials to each database.
Clean separation of data sets at the database level.
CONs
Transactions will not cross databases since the driver maintains a unique connection per database.
More administrative overhead associated with backing up and maintaining multiple databases.
The driver must have a separate set of connections open for each database and must switch context each time a file from a different database is accessed. This can add performance overhead depending on the order of calls and how frequently the switch is made.
Migrate each folder to a different schema¶
PROs
Clean distinction between “sets” of data while keeping everything in one database.
You can assign different permissions to each schema.
The list of tables in each schema is as small as possible.
No connection context switching since all schemas reside in the same database.
CONs
There is a little more administrative overhead maintaining the additional schemas.
On some backends, cross-schema queries may require additional permissions.
Migrate each folder using a different table prefix or suffix¶
PROs
This option is the easiest to implement.
The same approach works in all backends.
No connection context switching and no additional schemas to maintain.
CONs
The table list can become very large. For example, 300 data files across four customer folders results in 1,200 tables.
It is harder to assign separate user access control.
Oracle’s 30 character limit on identifiers can severely hinder this option.
Prefix vs. suffix: A prefix (e.g., EAST_Hours) groups tables by region, so all tables for a given region sort together. A suffix (e.g., Hours_EAST) groups tables by name, so all versions of the same table sort together. Choose whichever grouping makes the table list easier to navigate in your database management tools.
Consolidate the tables during migration¶
serv.db1.dbo.Hours
PROs
You have the fewest number of tables to maintain.
The same approach works in all backends.
CONs
The application code must be updated to merge data into shared tables.
There is no separate user access control.
Summary¶
Adding a table prefix or suffix during migration is the easiest and most commonly used option. However, if you have a large number of tables in each folder, the list on the server can become overwhelming.
If your application requires different credentials for different customer sets, separating the tables by schema is a good choice that avoids the connection overhead of multiple databases.
If load balancing or strict data isolation is important, using separate databases provides the strongest separation at the cost of additional administrative overhead and connection context switching.